infrastructure
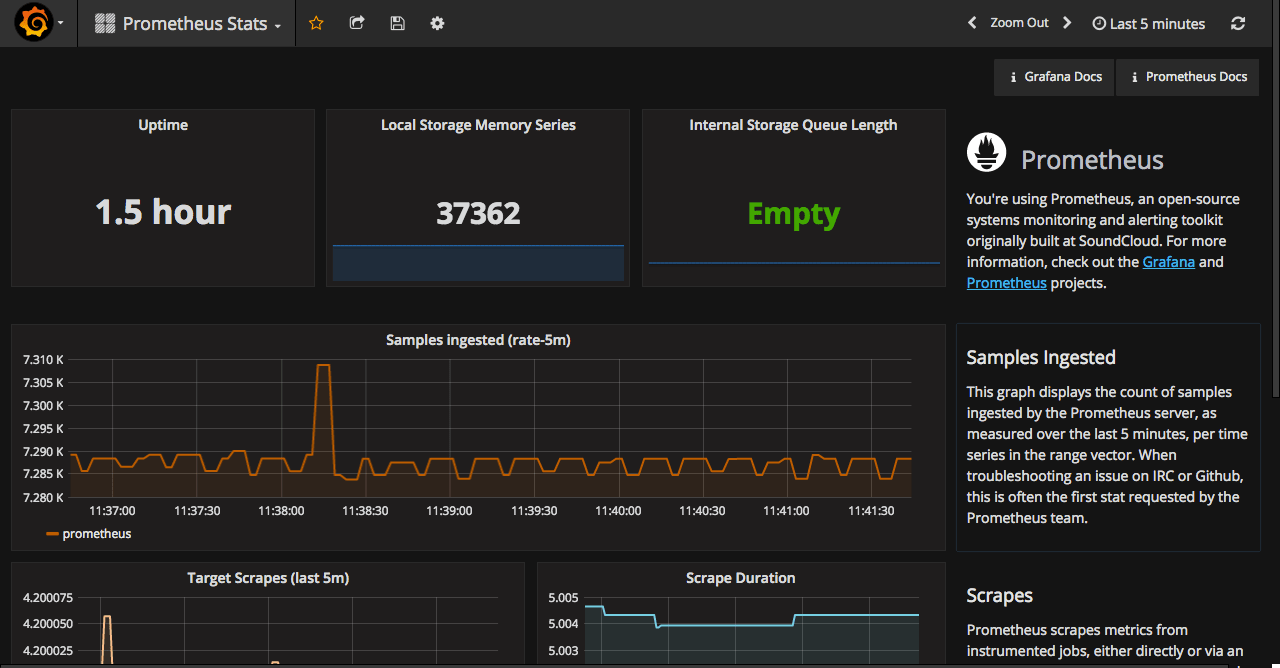
This post is one of a series of posts about monitoring of infrastructure and services. Other posts in the series:
Intro Deploying Prometheus and Grafana to Kubernetes (this article) Creating the first dashboard in Grafana 10 most useful Grafana dashboards to monitor Kubernetes and services Configuring alerts in Prometheus and Grafana Collecting errors from production using Sentry Making sense of logs with ELK stack Replacing commercial APM monitoring SLA, SLO, SLI and other useful abstractions I’ve been keeping my eye on Prometheus for some time.
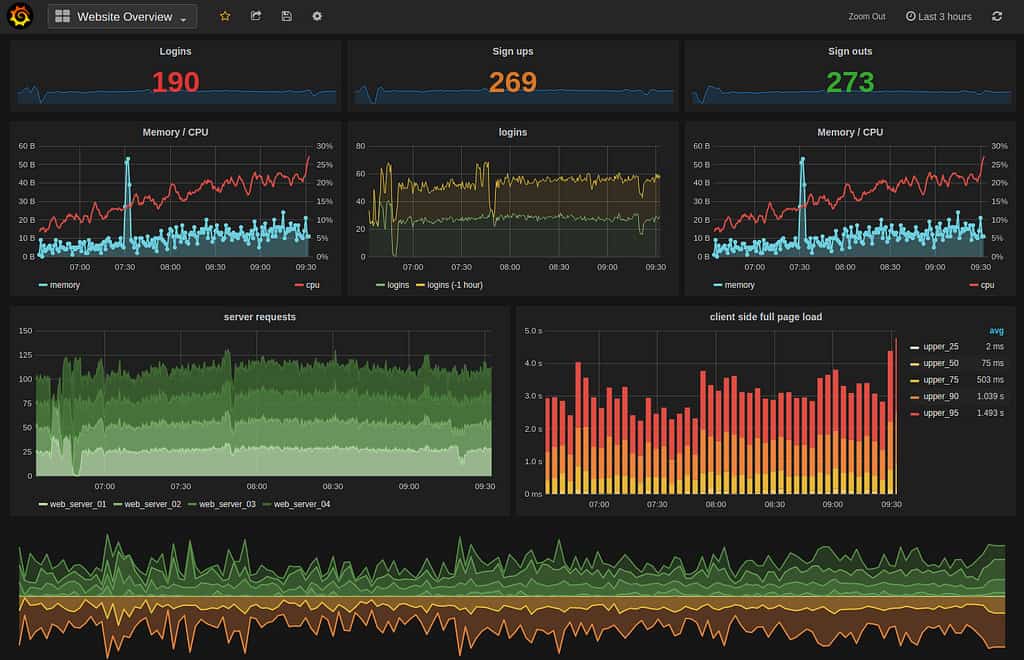
Intro (this article) Deploy and basic configuration of Prometheus Creating the first dashboard in Grafana 10 most useful Grafana dashboards to monitor Kubernetes and services Configuring alerts in Prometheus and Grafana Collecting errors from production using Sentry Making sense of logs with ELK stack Replacing commercial APM monitoring SLA, SLO, SLI and other useful abstractions Monitoring of the infrastructure is an essential part of any product. But it’s not uncommon for companies to postpone monitoring for the later period.

A few days ago when I tried to install helm chart in my Kubernetes cluster I noticed that all new pods that required storage were in pending state. After a quick check of the logs, I found out that pods were unable to get PVC from GlusterFS. I recently wrote about my experience deploying GlusterFS cluster. This time I will go through recovering data from the broken GlusterFS cluster, and some problems I faced deploying new cluster.

Since my previous posts[1][2] about CI/CD, a lot have changed. I started using Helm for packaging applications, stopped using docker-in-docker in gitlab-runner.
Recently, I started working on a few Golang microservices. I decided to try gitlab’s caching and split the job into multiple steps for better feedback in UI.
Few of the main changes to my .gitlab-ci.yaml file since my previous post:
no docker-in-docker using cache for packages instead of a prebuilt image with dependencies splitting everything into multiple steps.
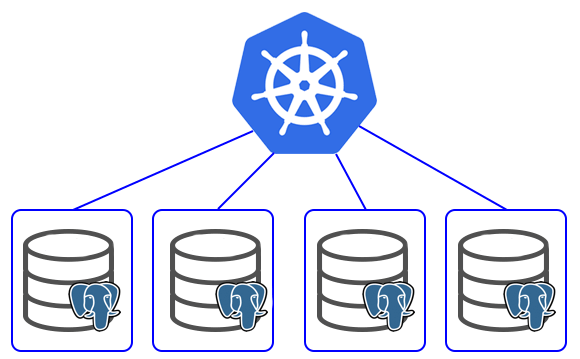
Creating a high available PostgreSQL cluster always was a tricky task. Doing it in the cloud environment is especially difficult. I found at least 3 projects trying to provide HA PostgreSQL solutions for Kubernetes.
Patroni
Patroni is a template for you to create your own customized, high-availability solution using Python and - for maximum accessibility - a distributed configuration store like ZooKeeper, etcd or Consul. Database engineers, DBAs, DevOps engineers, and SREs who are looking to quickly deploy HA PostgreSQL in the datacenter - or anywhere else - will hopefully find it useful.
