I’ve been looking for a good Continues Integration(CI) system for quite some time now. System, that could work with all the major repository providers and run on my hardware. The need for multi-provider support comes from the fact that my code is spread across:
Github Gitlab, cloud and self-hosted Gitea - I’m currently replacing my self-hosted Gitlab with it. I find it much simpler and faster. This means I can neither have a single view of all my tests nor have a unified way of testing.
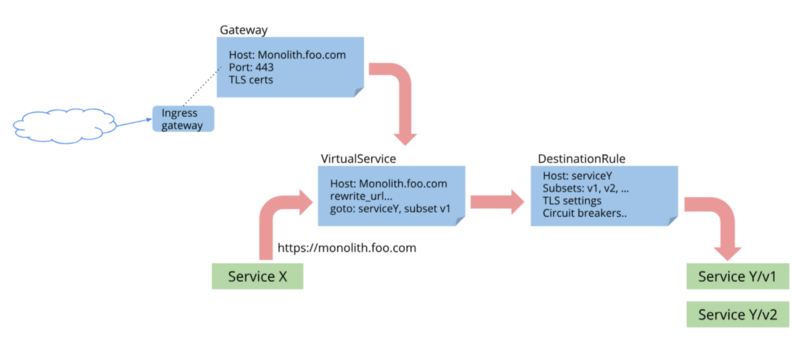
I’ve been following the news about istio since it’s first alpha release in 2017. I think this project has a great future, because it solves a lot of pain points in the microservice based architecture, like auth, observability, fault-injection, etc.
But the fact is, I never actually tried it. Prior to v1.0 there were too many bugs and limitations to put it into production. So, when they finally released “production-ready” version I got quite exciting.

How to deploy multi-arch Kubernetes cluster using Kubespray I recently bought 3 ODROID-HC1 devices to add a dedicated storage cluster to my home Kubernetes. I thought that it’s a good excuse to spend some time redeploying the cluster. Usually, I would’ve gone with CoreOS, since I’m a big fan of their immutable OS. Unfortunately, that is not an option if you have ARM nodes. So I had to choose between manual provisioning and Ansible.

Home Lab Infrastructure Overview Every software or technology I blog about usually goes through my home lab first. A lot of people usually got surprised when they first hear that I have a multi-node Kubernetes cluster at home. It usually takes some time to tell them about all the machines and networking. Of course, not accounting for the time spent answering the question “why do you need it”. I added a few new devices and reconfigured everything from scratch recently.
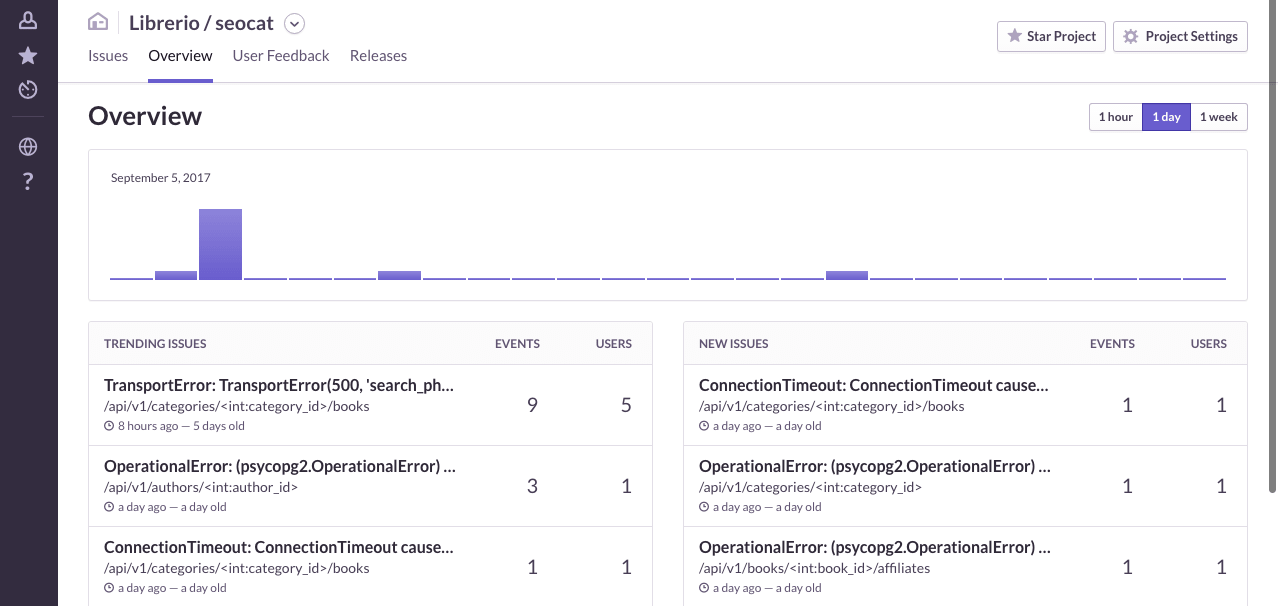
In this part of the series, I’m going to add Sentry to the monitoring stack. For those who do not know, Sentry is an open-source cross-platform crash reporting and aggregation platform written in Python. I know about it for several years now, since the time it supported only a few languages. A lot has changed since my last use of it: new domain, new languages, new integrations. Today it has integrations with most of the modern languages and frameworks like Elixir, React, React-Native, Go.
