
A few days ago when I tried to install helm chart in my Kubernetes cluster I noticed that all new pods that required storage were in pending state. After a quick check of the logs, I found out that pods were unable to get PVC from GlusterFS. I recently wrote about my experience deploying GlusterFS cluster. This time I will go through recovering data from the broken GlusterFS cluster, and some problems I faced deploying new cluster.
State: Peer Rejected
The first thing I noticed was the bad state of the peers.
$ kubectl exec -ti glusterfs0-2272744551-a4ghp gluster peer status
Number of Peers: 2
Hostname: XXX
Uuid: fd499492-e26f-4c3f-919a-57ebced1439a
State: State: Peer Rejected (Connected)
This case is covered in GlusterFS documentation.
NOTE: If you’ll find your peers in
Accepted peer requeststate after following the manual - restart glusterd one more time.
After all my nodes were in good state I tried to use storage again. It didn’t work, but I found this errors in heketi logs (I don’t remember if they where there before) :
[heketi] ERROR 2017/03/24 12:24:51 /src/github.com/heketi/heketi/apps/glusterfs/app_volume.go:148: Failed to create volume: Unable to execute command on glusterfs-6bjq2: volume create: vol_9d00fda936724e9f0500575f734b8fe3: failed: Brick: 192.168.11.69:/var/lib/heketi/mounts/vg_d16a4532c7879392d4546009d7dab6d0/brick_2830bc82e8836bb5913949ca32d0f8d4/brick not available. Brick may be containing or be contained by an existing brick.
[sshexec] ERROR 2017/03/24 12:24:48 /src/github.com/heketi/heketi/executors/sshexec/volume.go:139: Unable to delete volume vol_9d00fda936724e9f0500575f734b8fe3: Unable to execute command on glusterfs-6bjq2: volume delete: vol_9d00fda936724e9f0500575f734b8fe3: failed: Volume vol_9d00fda936724e9f0500575f734b8fe3 does not exist
I spent several hours trying to heal volumes using all possible commands from GlusterFS mailing lists, and different manual[1][2], but it didn’t help. Heal command showed that everything was fine. But old volumes were empty inside the PVC.
At some point, I realized that it’s easier to recreate the whole cluster. So I started to look how to get data from my volumes.
LVM intro
Since GlusterFS brick is not a usual partition, you can’t just mount it and copy your data. Instead, you need to access logical volumes created by GlusterFS. GlusterFS is using lvm (Logical Volume Manager) to create and manage storage. That means that it has 3 main types of objects:
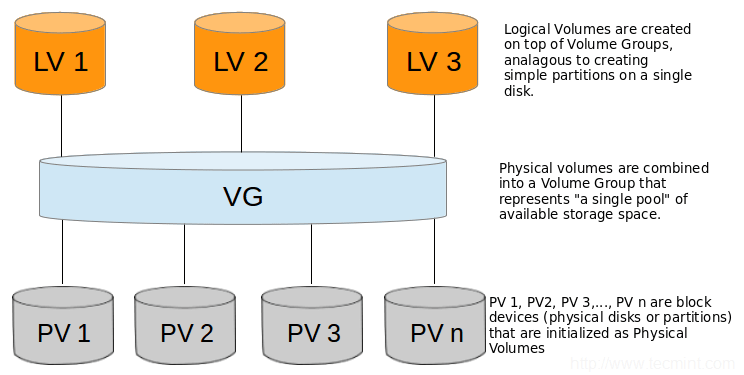
Volume group(VG) - the highest level of abstraction in lvm. It gathers collection of LV and PV
Physical Volume(PV) - usually hard disk or device that ‘looks’ like a hard disk
Logical Volume(LV) - an equivalent of a disk partition in usual system.
Here are some useful resources about logical volumes:
Recovering data
For recovery, we need to ssh to the data node. We will only need information about Logical Volumes, but for better understanding, I added similar commands for PV and VG.
Physical Volumes
# List all physical volumes
$ pvscan
PV /dev/sdd VG vg_af24fae4b067b6e1ff353d36b6a6918d lvm2 [1023.87 GiB / 861.94 GiB free]
Total: 1 [1023.87 GiB] / in use: 1 [1023.87 GiB] / in no VG: 0 [0 ]
# Display various attributes of physical volumes
$ pvdisplay
--- Physical volume ---
PV Name /dev/sdd
VG Name vg_af24fae4b067b6e1ff353d36b6a6918d
PV Size 1.00 TiB / not usable 132.00 MiB
Allocatable yes
PE Size 4.00 MiB
Total PE 262111
Free PE 220657
Allocated PE 41454
PV UUID eHxHEy-bMhv-rzF1-HOQn-ds1f-fs3T-GChR1p
Volume groups
$ vgscan
Reading all physical volumes. This may take a while...
Found volume group "vg_af24fae4b067b6e1ff353d36b6a6918d" using metadata type lvm2
$ vgdisplay
--- Volume group ---
VG Name vg_af24fae4b067b6e1ff353d36b6a6918d
System ID
Format lvm2
Metadata Areas 1
Metadata Sequence No 194
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 26
Open LV 13
Max PV 0
Cur PV 1
Act PV 1
VG Size 1023.87 GiB
PE Size 4.00 MiB
Total PE 262111
Alloc PE / Size 41454 / 161.93 GiB
Free PE / Size 220657 / 861.94 GiB
VG UUID Vhnkxf-HCHU-1USc-Y1fo-sNej-PNzr-fZXd3A
Logical Volumes
$ lvscan
ACTIVE '/dev/vg_af24fae4b067b6e1ff353d36b6a6918d/tp_32a08cbefd56fbdb4bcceba3b20ab4aa' [2.00 GiB] inherit
ACTIVE '/dev/vg_af24fae4b067b6e1ff353d36b6a6918d/brick_32a08cbefd56fbdb4bcceba3b20ab4aa' [2.00 GiB] inherit
ACTIVE '/dev/vg_af24fae4b067b6e1ff353d36b6a6918d/tp_8a72359bb8912053e87af7cf411282ab' [15.00 GiB] inherit
ACTIVE '/dev/vg_af24fae4b067b6e1ff353d36b6a6918d/brick_8a72359bb8912053e87af7cf411282ab' [15.00 GiB] inherit
ACTIVE '/dev/vg_af24fae4b067b6e1ff353d36b6a6918d/tp_b9b58b673d04adc56531bc4553c566e8' [20.00 GiB] inherit
ACTIVE '/dev/vg_af24fae4b067b6e1ff353d36b6a6918d/brick_b9b58b673d04adc56531bc4553c566e8' [20.00 GiB] inherit
$ lvdisplay
--- Logical volume ---
LV Name tp_32a08cbefd56fbdb4bcceba3b20ab4aa
VG Name vg_af24fae4b067b6e1ff353d36b6a6918d
LV UUID ySroXS-reeP-L3mh-PJ8F-JzXS-8IWE-BubioM
LV Write Access read/write
LV Creation host, time server.example.com, 2017-03-25 14:54:02 +0100
LV Pool metadata tp_32a08cbefd56fbdb4bcceba3b20ab4aa_tmeta
LV Pool data tp_32a08cbefd56fbdb4bcceba3b20ab4aa_tdata
LV Status available
# open 2
LV Size 2.00 GiB
Allocated pool data 0.71%
Allocated metadata 0.33%
Current LE 512
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 252:2
--- Logical volume ---
LV Path /dev/vg_af24fae4b067b6e1ff353d36b6a6918d/brick_32a08cbefd56fbdb4bcceba3b20ab4aa
LV Name brick_32a08cbefd56fbdb4bcceba3b20ab4aa
VG Name vg_af24fae4b067b6e1ff353d36b6a6918d
LV UUID QHUP2i-n2Tv-zz89-xpke-dr34-4jAJ-SJ286F
LV Write Access read/write
LV Creation host, time server.example.com, 2017-03-25 14:54:03 +0100
LV Pool name tp_32a08cbefd56fbdb4bcceba3b20ab4aa
LV Status available
# open 1
LV Size 2.00 GiB
Mapped size 0.71%
Current LE 512
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 252:4
--- Logical volume ---
LV Name tp_8a72359bb8912053e87af7cf411282ab
VG Name vg_af24fae4b067b6e1ff353d36b6a6918d
LV UUID C7TByo-VdOq-mL1y-sdyY-7Pza-4IxI-1k3kxs
LV Write Access read/write
LV Creation host, time server.example.com, 2017-03-25 16:43:06 +0100
LV Pool metadata tp_8a72359bb8912053e87af7cf411282ab_tmeta
LV Pool data tp_8a72359bb8912053e87af7cf411282ab_tdata
LV Status available
# open 2
LV Size 15.00 GiB
Allocated pool data 0.12%
Allocated metadata 0.07%
Current LE 3840
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 252:7
--- Logical volume ---
LV Path /dev/vg_af24fae4b067b6e1ff353d36b6a6918d/brick_8a72359bb8912053e87af7cf411282ab
LV Name brick_8a72359bb8912053e87af7cf411282ab
VG Name vg_af24fae4b067b6e1ff353d36b6a6918d
LV UUID zuUtZB-oRJP-lmZt-Qmn2-j8ta-LR3k-4rH2VA
LV Write Access read/write
LV Creation host, time server.example.com, 2017-03-25 16:43:07 +0100
LV Pool name tp_8a72359bb8912053e87af7cf411282ab
LV Status available
# open 1
LV Size 15.00 GiB
Mapped size 0.12%
Current LE 3840
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 252:9
What we need from all of this is the output of the lvdisplay command. Specifically its LV Path .
Because we can mount it as a usual disk.
$ mount /dev/vg_d16a4532c7879392d4546009d7dab6d0/brick_be8a8a7cbf5239caa185cb8d00ae4cfd /mount/volume1
Since I had more than 30 of GlusterFS volumes, I ended up with this bash one-liner. It mounts each volume to its own directory.
$ cd your-target-directory
$ for i in $(lvdisplay | grep /dev/ | cut -d" " -f20); do DIR="${i##/*/}"; echo $DIR; mkdir $DIR; mount $i $DIR; done
$ ls
brick_be8a8a7cbf5239caa185cb8d00ae4cfd
brick_8a72359bb8912053e87af7cf411282ab
...
Now you can inspect volumes and copy your data from the bricks as usual.
Deploy new cluster
All data save and disks are clean. Time to deploy GlusterFS again. I was very interested to see whether anything has changed since my previous experience. So I decided to follow the installation manual from the beginning.
I was pleasantly surprised that I didn’t face any of the problems I had before. It’s probably due to the non-fresh system. Instead, I faced a new problem because of the this.
> $ heketi-cli topology load --json=topology-sample.json Found node node-03 on cluster b55122d933d2a850f69524d9758c7c49
Adding device /dev/sdb ... Unable to add device: Unable to execute command on glusterfs-b0n9m: WARNING: Not using lvmetad because config setting use_lvmetad=0.
WARNING: To avoid corruption, rescan devices to make changes visible (pvscan --cache).
Can't open /dev/sdb exclusively. Mounted filesystem?
Found node node-02 on cluster b55122d933d2a850f69524d9758c7c49
Adding device /dev/sdb ... Unable to add device: Unable to execute command on glusterfs-xnftq: WARNING: Not using lvmetad because config setting use_lvmetad=0.
WARNING: To avoid corruption, rescan devices to make changes visible (pvscan --cache).
Can't open /dev/sdb exclusively. Mounted filesystem?
Found node node-01 on cluster b55122d933d2a850f69524d9758c7c49
Adding device /dev/sdd ... Unable to add device: Unable to execute command on glusterfs-x4kdf: WARNING: Not using lvmetad because config setting use_lvmetad=0.
WARNING: To avoid corruption, rescan devices to make changes visible (pvscan --cache).
Can't open /dev/sdd exclusively. Mounted filesystem?
Running pvscan --cache as suggested didn’t help. Neither as deleting all LV, VG, PV.
It didn’t work even after a reboot.
At the end, I found the solution on stackoverflow.
$ dmsetup remove sdX
dmsetup is some kind of low-level utility to work with lvm. More information could be found here
Anyway, I continued to follow the manual
$ heketi-cli setup-openshift-heketi-storage
$ kubectl create -f heketi-storage.json
At this point everything was fine. Running heketi-cli topology info returned me all my nodes and volumes.
Then I deleted all helper objects and deployed heketi-deployment
# kubectl delete all,service,jobs,deployment,secret --selector="deploy-heketi"
# kubectl create -f heketi-deployment.json
service "heketi" created
deployment "heketi" created
After this, heketi-cli cluster info returned me nothing.
I thought that may be I didn’t wait until the end of deployment job to finish. Following the manual for the second time gave me the same result.
After some debugging, I traced the problem to the empty heketi.db in heketi-db-backup secret.
Setting heketi.db value from the generated heketi-storage.json file seems to fix the issue.
Conclusion
I don’t know what caused the problem with my storage. One of the guesses is some network related issue. I didn’t lose any of the data but there were some scary moments :).
I will continue to use GlusterFS on staging cluster, but for now, I’m not ready to use it in production.

Share this post
Twitter
Google+
Facebook
Reddit
LinkedIn
StumbleUpon
Email