Generation of sitemaps is usually not a problem, at least not until you have several millions of items in the database to iterate through. Currently, I have slightly more than 4M documents, so it takes time to regenerate. Previously all my sitemaps were stored on the disk and were served using simple Nginx container. It worked like this:
Sitemap-related containers have nodeSelector to assign to particular node with hostPath volume sitemaps are served from /data/sitemaps folder periodic task generates new sitemaps to /data/sitemaps-temp on completion, folders is atomically switched It was fine in my previous VM-based cluster, which was on a single physical machine.
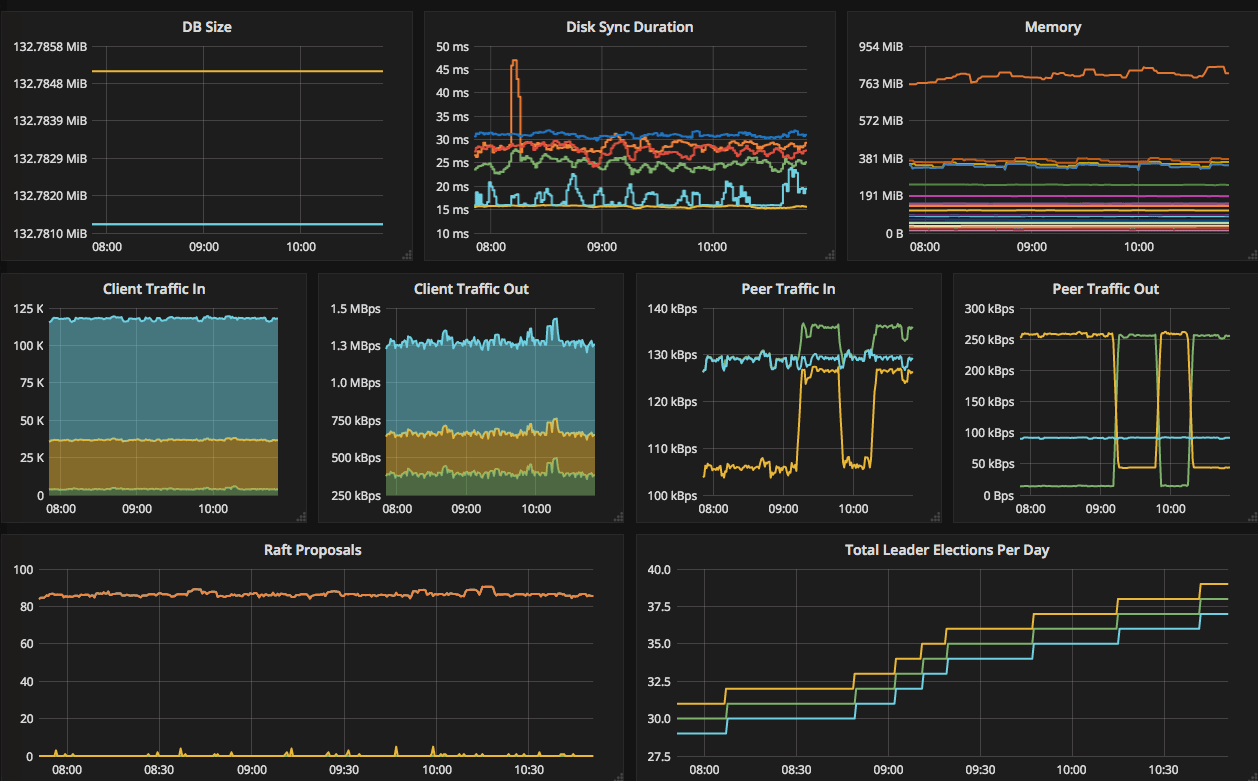
This post is one of a series of posts about monitoring of infrastructure and services. Other posts in the series:
Intro Deploying Prometheus and Grafana to Kubernetes Creating the first dashboard in Grafana 10 most useful Grafana dashboards to monitor Kubernetes and services (this article) Configuring alerts in Prometheus and Grafana Collecting errors from production using Sentry Making sense of logs with ELK stack Replacing commercial APM monitoring SLA, SLO, SLI and other useful abstractions There are dozens of ready dashboards available on grafana.
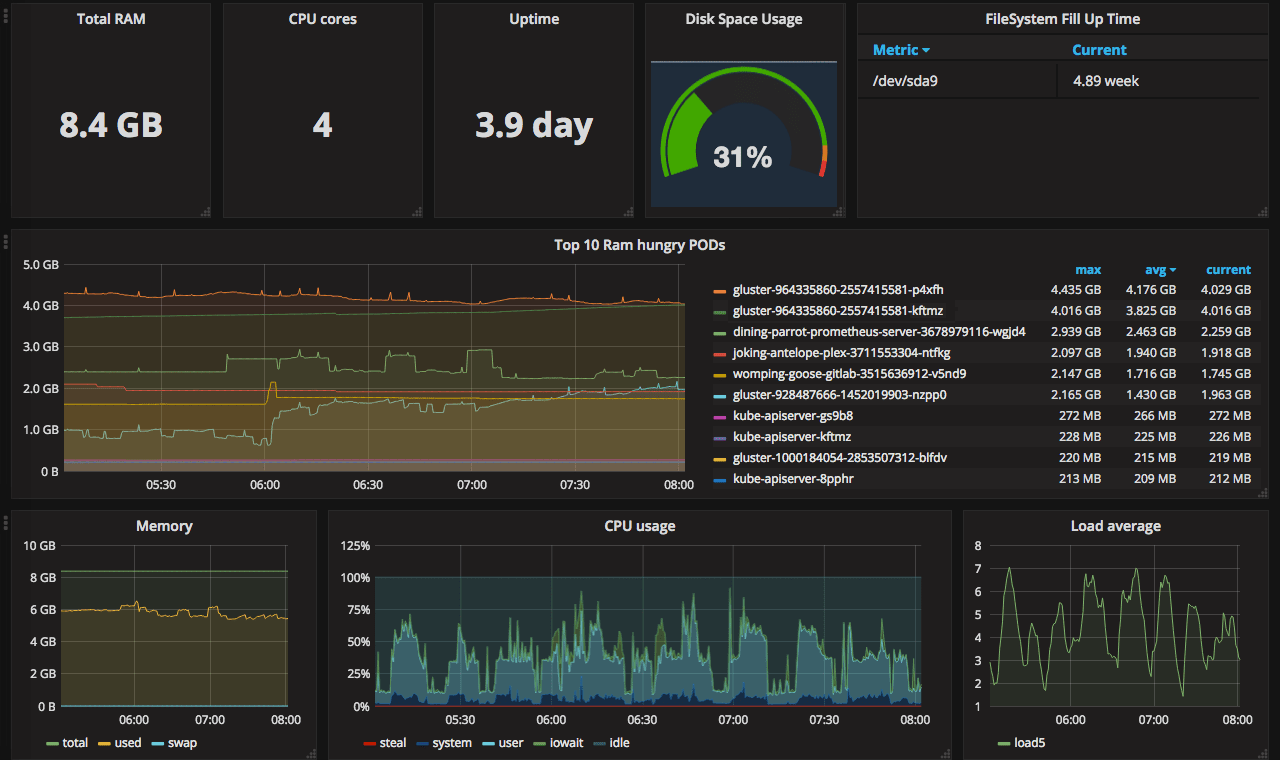
This post is one of a series of posts about monitoring of infrastructure and services. Other posts in the series:
Intro Deploying Prometheus and Grafana to Kubernetes Creating the first dashboard in Grafana (this article) 10 most useful Grafana dashboards to monitor Kubernetes and services Configuring alerts in Prometheus and Grafana Collecting errors from production using Sentry Making sense of logs with ELK stack Replacing commercial APM monitoring SLA, SLO, SLI and other useful abstractions Having grafana.
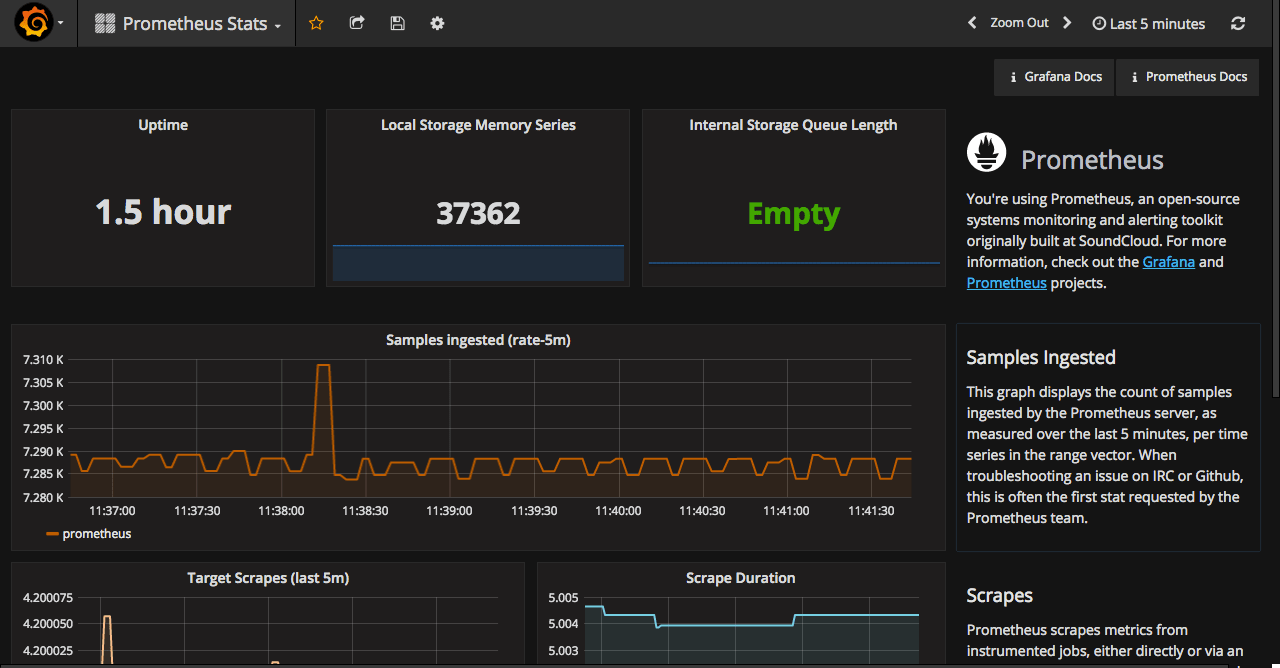
This post is one of a series of posts about monitoring of infrastructure and services. Other posts in the series:
Intro Deploying Prometheus and Grafana to Kubernetes (this article) Creating the first dashboard in Grafana 10 most useful Grafana dashboards to monitor Kubernetes and services Configuring alerts in Prometheus and Grafana Collecting errors from production using Sentry Making sense of logs with ELK stack Replacing commercial APM monitoring SLA, SLO, SLI and other useful abstractions I’ve been keeping my eye on Prometheus for some time.
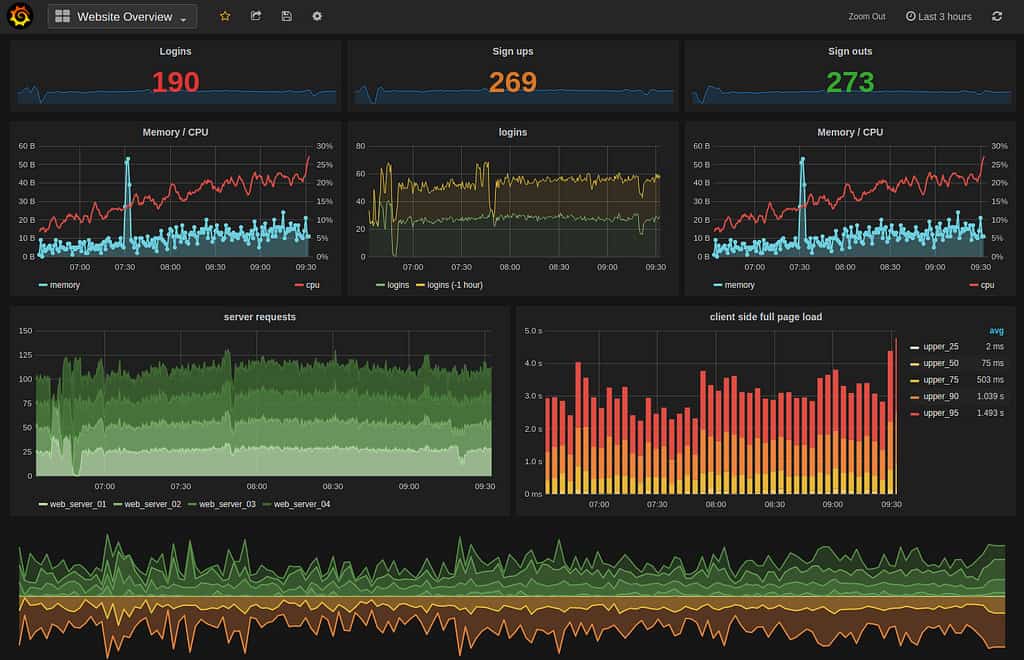
Intro (this article) Deploy and basic configuration of Prometheus Creating the first dashboard in Grafana 10 most useful Grafana dashboards to monitor Kubernetes and services Configuring alerts in Prometheus and Grafana Collecting errors from production using Sentry Making sense of logs with ELK stack Replacing commercial APM monitoring SLA, SLO, SLI and other useful abstractions Monitoring of the infrastructure is an essential part of any product. But it’s not uncommon for companies to postpone monitoring for the later period.
