Creating a high available PostgreSQL cluster always was a tricky task. Doing it in the cloud environment is especially difficult. I found at least 3 projects trying to provide HA PostgreSQL solutions for Kubernetes.
Patroni is a template for you to create your own customized, high-availability solution using Python and - for maximum accessibility - a distributed configuration store like ZooKeeper, etcd or Consul. Database engineers, DBAs, DevOps engineers, and SREs who are looking to quickly deploy HA PostgreSQL in the datacenter - or anywhere else - will hopefully find it useful.
Crunchy Container Suite provides Docker containers that enable rapid deployment of PostgreSQL, including administration and monitoring tools. Multiple styles of deploying PostgreSQL clusters are supported.
Stolon is a cloud native PostgreSQL manager for PostgreSQL high availability. It’s cloud native because it’ll let you keep an high available PostgreSQL inside your containers (kubernetes integration) but also on every other kind of infrastructure (cloud IaaS, old style infrastructures etc…)
Nice diagram in the repo and few guest posts1 2 on kubernetes.io convinced me to try crunchy-containers. But after some time spent with it I changed my mind. I don’t want to say that something is broken or badly designed. But, for me, it looks like a manually installed PostgreSQL packed in a docker containers. It doesn’t feel like it was made for clouds. So, I went with a stolon. After several iterations of installs/destroys I took the statefulset example and created helm chart. If you want to read more about stolon - check out this introduction post from the author. Below I will go through the installation process and how to test failover of the cluster. I assume the installation using my helm chart.
Stolon architecture
(taken from the stolon introduction)
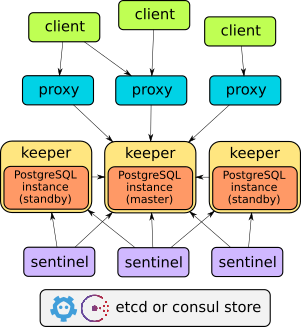
Stolon is made up of 3 main components:
- keeper: it manages a PostgreSQL instance converging to the clusterview provided by the sentinel(s).
- sentinel: it discovers and monitors keepers and calculates the optimal clusterview.
- proxy: the client’s access point. It enforces connections to the right PostgreSQL master and forcibly closes connections to unelected masters.
Stolon uses etcd or consul as a main storage for cluster state.
Installation
git clone https://github.com/lwolf/stolon-chart
cd stolon-chart
helm install ./stolon
During install, a few things will happen. First of all 3 node etcd cluster will be created using statefulset. Stolon-proxy and stolon-sentinel will also be deployed. Singe time job for cluster initialisation will wait until etcd cluster became available.
The chart will also create 2 services:
- stolon-proxy - service from official example. It always points to the current master and should be used for writes.
- stolon-keeper - Stolon itself do not currently provide any solution for balancing reads. But Kubernetes services can handle it. for us. This one will balance reads between all keeper pods.
After everything will be in the RUNNING state we can try to connect.
We can deploy services with type NodePort for simplify connection. Use separate terminals to connect to the master and slave services. During this post, I will assume that stolon-proxy service (RW) is exposed to port 30543 and stolon-keeper service (RO) is exposed to 30544
Connect to the master and create test table
psql --host <IP> --port 30543 postgres -U stolon -W
postgres=# create table test (id int primary key not null, value text not null);
CREATE TABLE
postgres=# insert into test values (1, 'value1');
INSERT 0 1
postgres=# select * from test;
id | value
----+--------
1 | value1
(1 row)
Connect to the slave and check the data. You can try to write something to make sure that requests are handled by slave.
psql --host <IP> --port 30544 postgres -U stolon -W
postgres=# select * from test;
id | value
----+--------
1 | value1
(1 row)
After everything works, let’s test the failover.
Testing failover
1. Simulate master death
This case is covered in the statefullset example in the official repository. In short to simulate death of the master we need to kill statefulset and then delete the current master pod. Statefulset needs to be deleted since otherwise, it will recreate pod before the sentinel notice that it’s dead.
kubectl delete statefulset stolon-keeper --cascade=false
kubectl delete pod stolon-keeper-0
After this, we can see in the sentinel logs that new master was successfully elected.
no keeper info available db=cb96f42d keeper=keeper0
no keeper info available db=cb96f42d keeper=keeper0
master db is failed db=cb96f42d keeper=keeper0
trying to find a standby to replace failed master
electing db as the new master db=087ce88a keeper=keeper1
Now if we redo the previous command in both psql sessions we should see something like this.
postgres=# select * from test;
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
The connection to the server was lost. Attempting reset: Succeeded.
postgres=# select * from test;
id | value
----+--------
1 | value1
(1 row)
Kubernetes service will remove failed pods and balance requests only between live pods. So, new read sessions will be routed to healthy pods.
Afterward we need to recreate our statefulset. The easiest way to do it is by upgrading deployed helm chart.
helm ls
NAME REVISION UPDATED STATUS CHART NAMESPACE
factual-crocodile 1 Sat Feb 18 15:42:50 2017 DEPLOYED stolon-0.1.0 default
helm upgrade factual-crocodile .
2. Simulate random pods death with chaoskube
Another good way to test the resilience of the cluster is to use chaoskube. Chaoskube is a small service which periodically kills random pods in the cluster.
It also could be deployed using helm charts.
helm install --set labels="release=factual-crocodile,component!=factual-crocodine-etcd" --set interval=5m stable/chaoskube
This will run chaoskube which will delete one pod every five minutes. It will select pods with label release=factual-crocodile , but will ignore etcd pods.
After few hours of such testing my cluster was still consistent and worked pretty stable.
Conclusion
I’m still trying stolon on my staging servers. But I’m pretty happy with it so far. It really feels like a cloud native service. Easily scalable and with good automatic failover.
If you interested in trying it - check out the official repository and my chart.

{kind=link}
Share this post
Twitter
Google+
Facebook
Reddit
LinkedIn
StumbleUpon
Email